Performance Myths : Clustered vs. Non-Clustered Indexes
'I was recently scolded for suggesting that, in some cases, a non-clustered index will perform better for a particular query than the clustered index. This person stated that the clustered index is always best because it is always covering by definition, and that any non-clustered index with some or all of the same key columns was always redundant.
I will happily agree that the clustered index is always covering (and to avoid any ambiguity here, we're going to stick to disk-based tables with traditional B-tree indexes).
 I disagree, though, that a clustered index is always faster than a non-clustered index. I also disagree that it is always redundant to create a non-clustered index or unique constraint consisting of the same (or some of the same) columns in the clustering key.
I disagree, though, that a clustered index is always faster than a non-clustered index. I also disagree that it is always redundant to create a non-clustered index or unique constraint consisting of the same (or some of the same) columns in the clustering key.
Let's take this example, Warehouse.StockItemTransactions, from WideWorldImporters. The clustered index is implemented through a primary key on just the StockItemTransactionID column (pretty typical when you have some kind of surrogate ID generated by an IDENTITY or a SEQUENCE).
It's a pretty common thing to require a count of the whole table (though in many cases there are better ways). This can be for casual inspection or as part of a pagination procedure. Most people will do it this way:
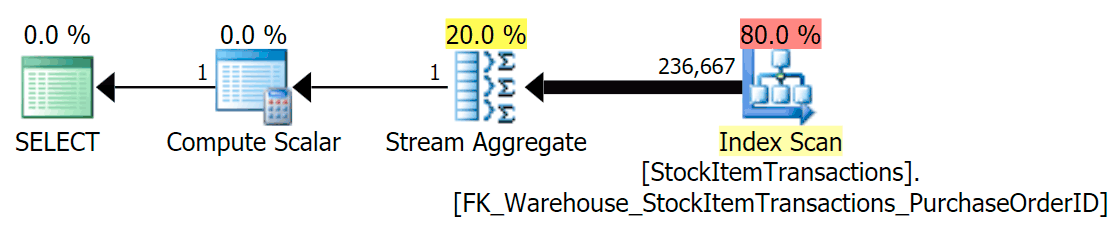
SELECT COUNT(*)
FROM Warehouse.StockItemTransactions;
With the current schema, this will use a non-clustered index:
'...
https://sqlperformance.com/2017/03/sql-indexes/performance-myths-clustered-vs-non-clustered
Trackbacks
Die Kommentarfunktion wurde vom Besitzer dieses Blogs in diesem Eintrag deaktiviert.
Kommentare
Ansicht der Kommentare: Linear | Verschachtelt